
 Richtlinien zur Einreichung von Proben
Richtlinien zur Einreichung von Proben
Was ist die Wiederverwendung von Medikamenten?
Die Wiederverwendung von Medikamenten, manchmal auch als Neupositionierung von Medikamenten bezeichnet, ist eine intelligente Methode zur Entwicklung neuer Therapien unter Verwendung bestehender Verbindungen. Anstatt von Grund auf neu zu beginnen, identifiziert dieser Ansatz neue Krankheitsbereiche, in denen ein bekanntes Medikament wirksam sein könnte.
Da diese Medikamente bereits über Sicherheits-, Toxizitäts- und Pharmakokinetikdaten verfügen, können Forscher einen Großteil der frühen Entwicklungsphasen überspringen. Das bedeutet schnellere Zeitpläne, geringere Kosten und weniger Risiken – insbesondere bei der Bekämpfung dringender Bereiche wie seltenen Krankheiten, Krebs oder neu auftretenden Infektionen.
Einige der größten Vorteile der Wiederverwendung von Medikamenten sind:
- Den Weg vom Labor zur Klinik um Jahre verkürzen.
- Senkung der F&E-Kosten um bis zu 60 % im Vergleich zur traditionellen Entdeckung
- Wiederbelebung eingestellter Vermögenswerte oder Verlängerung des Lebenszyklus bestehender Medikamente
- In einer Zeit steigender Entwicklungskosten bietet die Wiederverwendung von Medikamenten einen praktischen, datengestützten Weg zur Innovation.
Unsere Lösung zur Wiederverwendung von Medikamenten
Eine flexible Strategie, die auf dem Potenzial Ihres Medikaments basiert.
Bei CD Genomics erkennen wir an, dass kein zwei Wiederverwendungsprojekte gleich sind. Deshalb bieten wir eine umfassende Palette maßgeschneiderter Dienstleistungen an. Medikamentenumpositionierungsstrategien—jede darauf ausgelegt, neuen therapeutischen Wert aus Ihren bestehenden Vermögenswerten zu erschließen. Egal, ob Sie mit kleinen Molekülen, Biologika oder eingelagerten Verbindungen arbeiten, wir helfen Ihnen, schnellere und kostengünstigere Wege auf den Markt zu finden.
Unser Ansatz geht über statische Pipelines hinaus. Wir kombinieren biologisches Wissen, KI-gestützte Analysen und pfadgesteuertes Modellieren, um zu identifizieren. hochgradig vertrauenswürdige Wiederverwendungs-Kandidaten ausgerichtet auf Ihre Forschungsziele und therapeutischen Interessengebiete.
Hier ist, wie wir Ihr Projekt zur Wiederverwendung von Medikamenten aus mehreren Perspektiven unterstützen:

Arzneimittelzentrierte Umnutzung
Ordnen Sie bekannte Verbindungen alternativen Zielen oder Krankheitswegen zu, basierend auf dem Wirkmechanismus oder dem molekularen Profil.
Krankheitszentrierte Wiederverwendung
Identifizieren Sie Medikamente, die Krankheitsnetzwerke ähnlich Ihrer Interessensindikation beeinflussen können – ideal für seltene oder aufkommende Krankheiten.
Zielzentrierte Umnutzung
Konzentrieren Sie sich auf ein biologisches Ziel von Interesse und entdecken Sie zuvor zugelassene Medikamente, die mit ihm interagieren.
Therapeutisch zentrierte Umnutzung
Erweitern Sie Ihr Produktportfolio, indem Sie verwandte therapeutische Klassen identifizieren, in denen Ihr Wirkstoff wirksam sein kann.
Wiederverwendung auf Basis großer Moleküle
Erforschen Sie neue Anwendungen für Biologika, monoklonale Antikörper oder Peptide mithilfe von omikagestützter Pfadanalyse.
Hochdurchsatz-Anzeigescanning
Nutzen Sie KI und Datenanalyse, um Ihr Molekül schnell über Hunderte von Krankheitsindikationen hinweg zu bewerten.
Umnutzung von Tierarzneimitteln
Übersetzen Sie Daten zu menschlichen Arzneimitteln in umsetzbare Erkenntnisse für Anwendungen im Bereich der Tiergesundheit.
Reformulierung und Arzneimittel-Kombinationsstrategien
Die Wirksamkeit steigern oder die Toxizität reduzieren, indem neue Darreichungsformen oder synergistische Kombinationen erforscht werden.
Strategien für das Lebenszyklusmanagement von Arzneimitteln
Maximieren Sie den ROI, indem Sie neue Märkte identifizieren, die Exklusivität verlängern oder alternde Vermögenswerte für unerfüllte Bedürfnisse umpositionieren.
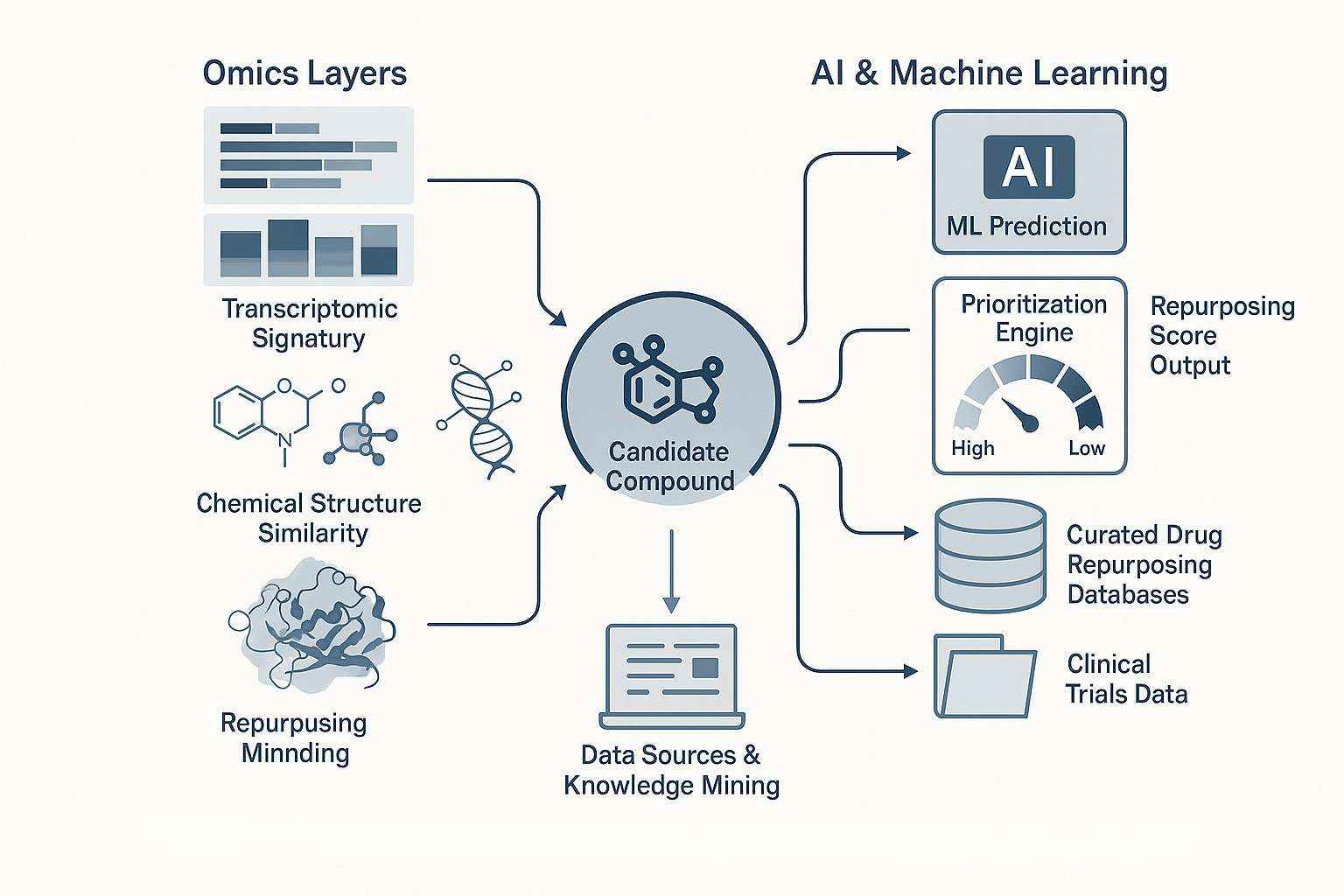
Unser bioinformatischer Ansatz
Daten, Biologie und KI zusammenbringen, um die in silico Arzneimittelumwidmung voranzutreiben.
Im Kern unserer Dienstleistungen zur Wiederverwendung von Arzneimitteln steht ein robustes computational bioinformatische Pipeline—speziell entwickelt, um neuartige Arzneimittel-Krankheits-Beziehungen durch integrierte Omik-Analysen, maschinelles Lernen und Netzwerkmodellierung aufzudecken.
Wir verlassen uns nicht auf eine einzige Datenquelle oder einen Algorithmus. Stattdessen kombinieren wir mehrere Schichten biologischer Evidenz – Genexpression, Struktur, Interaktion und Phänotyp – in einem einheitlichen Rahmen, der fundierte Entscheidungen zur Neupositionierung leitet. Ob Sie Hunderte von Verbindungen screenen oder ein einzelnes Asset validieren, unser Ansatz gibt Ihnen die Klarheit, um voranzukommen.
So machen wir das:
Transkriptomisches Signatur-MatchingIdentifizieren Sie Verbindungen mit Genexpressionsprofilen, die denen ähneln, von denen bekannt ist, dass sie für die angestrebte Indikation wirksam sind.
Genexpressionsprofilierung & Weganreicherung: Offenbaren Sie relevante biologische Signalwege und Krankheitsmechanismen, die von Ihrem Kandidatenverbindung beeinflusst werden.
Strukturelle und molekulare ÄhnlichkeitsmodellierungVergleichen Sie die Struktur Ihres Verbindungsstoffs mit bekannten Medikamenten, um wahrscheinliche Aktivitäten oder Off-Target-Effekte abzuleiten.
Medikament-Ziel-Krankheits-Netzwerk-KartierungVisualisieren und analysieren Sie Verbindungen zwischen chemischen Entitäten, molekularen Zielen und Krankheitsphänotypen mithilfe graphbasierter Modelle.
Kuratierten Datenbanken zur Wiederverwendung von MedikamentenIntegrieren Sie proprietäre und öffentliche Datensätze, um datengestützte Priorisierungsstrategien zu unterstützen.
Maschinelles Lernen für Vorhersage und PriorisierungNutzen Sie KI-Modelle, um vorherzusagen, welche Verbindungen mit hoher Wahrscheinlichkeit erfolgreich sind, basierend auf historischen und experimentellen Daten.
Literatur- und öffentliche DatenbankanalyseNutzen Sie meine wissenschaftlichen Publikationen, klinischen Studien und Pharmakovigilanzquellen, um umsetzbare Erkenntnisse zu gewinnen.
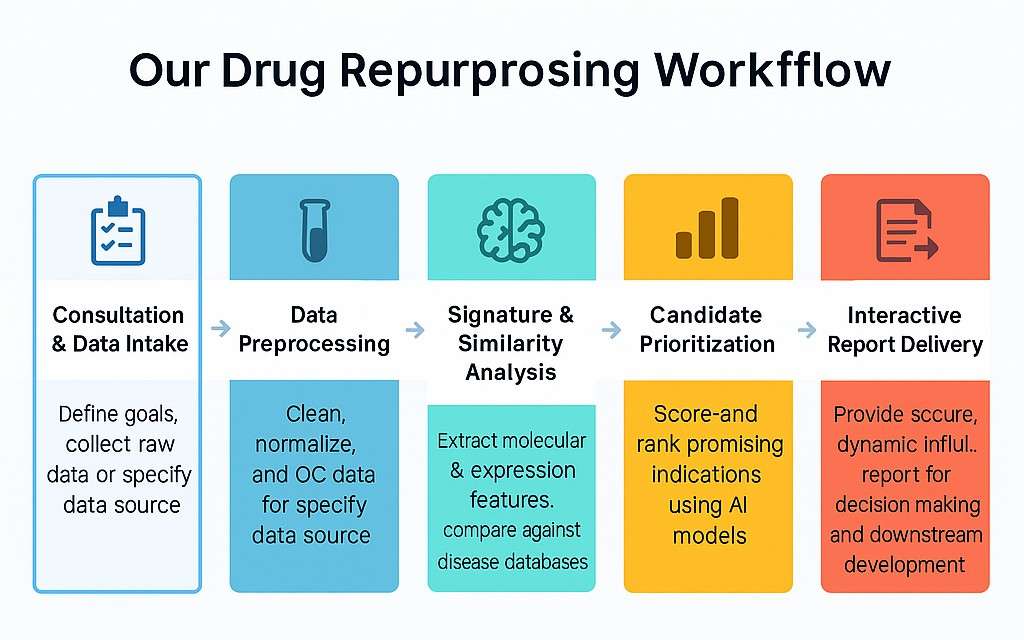
Unser Arbeitsablauf
Eine flexible Pipeline, die auf Ihre Daten, Ziele und Zeitpläne zugeschnitten ist.
- Beratung & Datenerfassung
Wir stimmen uns auf Ihre Ziele, Zielindikationen und verfügbaren Daten (intern oder öffentlich) ab.
- Datenvorverarbeitung
Rohdatensätze werden bereinigt und normalisiert, um die Analysequalität und Konsistenz sicherzustellen.
- Signatur- und Ähnlichkeitsanalyse
Wir extrahieren transkriptomische und molekulare Signaturen und gleichen sie dann mit bekannten Krankheitsprofilen ab.
- Vorhersage des Wirkmechanismus
Wegweiser und biologische Ziele, die durch die Verbindung beeinflusst werden, werden kartiert und interpretiert.
- Kandidatenpriorisierung
Mit KI-Modellen bewerten und rangieren wir Wiederverwendungsgelegenheiten basierend auf biologischer Relevanz und Neuheit.
- Berichtszustellung
Die Ergebnisse werden in einem sicheren, interaktiven HTML-Bericht bereitgestellt – bereit, Ihren nächsten Forschungsschritt zu leiten.
Hauptvorteile
Warum Forscher und Entwickler CD Genomics wählen
🔹 Schnelle, KI-gesteuerte Analyse
Automatisierte Algorithmen beschleunigen die Entdeckung von Kandidaten und die Zuordnung von Indikationen.
🔹 Geringere Kosten und Risiko
Geringere F&E-Investitionen im Vergleich zu de novo Arzneimittelentwicklungswegen.
🔹 Mechanismusbasierte Vorhersagen
Einblicke, die auf biologischen Wegen und molekularen Zielen basieren.
🔹 Flexible Dateninputs
Unterstützt Roh- oder vorverarbeitete Daten aus internen oder externen Quellen.
🔹 Vollständig dokumentiert und reproduzierbar
Jedes Ergebnis umfasst die Rückverfolgbarkeit der Methode und versionierte Pipelines.
🔹 Skalierbar für jede Projektgröße
Anpassbar für Startups, Akademien und Arbeitsabläufe in der großen Pharmaindustrie.
🔹 Nur für Forschungszwecke
Keine klinischen Ansprüche oder regulatorischen Hürden – ideal für die Erforschung in frühen Phasen.
Liefergegenstände
Klare, umsetzbare Ergebnisse, um Ihren nächsten Schritt zu leiten.
Interaktiver HTML-Bericht
Ein sicherer, passwortgeschützter Bericht, der auf unserem Server gehostet wird. Vollständig klickbar, durchsuchbar und strukturiert für eine einfache Navigation – keine spezielle Software erforderlich.
Rangliste der Wiederverwendungs-Kandidaten
Jeder Kandidat wird nach biologischer Relevanz, transkriptomischer Ähnlichkeit, struktureller Passung und maschinenlernbasierter Wiederverwendbarkeit bewertet.
Zusammenfassung des Wirkmechanismus
MoA-Hypothesen für jeden Kandidaten, unterstützt durch Pfadanalyse, bekannte Ziele und Literaturverweise.
Visualisierungen & Netzwerkdiagramme
Weganreicherungsdiagramme, Arzneimittel-Ziel-Krankheits-Interaktionsnetzwerke und Cluster-Hitzekarten – bereit für Präsentation oder Veröffentlichung.
Vollständige Methodikdokumentation
Eine klare Aufzeichnung der verwendeten Werkzeuge, Parameter, Datenbanken und Bewertungsmodelle—um vollständige Reproduzierbarkeit und regulatorische Transparenz zu gewährleisten.
Optionale Zusatzleistungen
Benutzerdefinierte Formatierungen (z. B. Excel-Export), Empfehlungen für nachgelagerte Analysen oder beratende Überprüfungssitzungen können auf Anfrage aufgenommen werden.
Warum CD Genomics?
Ein Partner für datengestützte Arzneimittelentdeckung.
- Über 15 Jahre Erfahrung in Omics und computergestützter Biologie
- Anpassbare Workflows, die auf Ihre Verbindung und Indikation zugeschnitten sind.
- Sicheres, vertrauliches und nur für Forschungszwecke verwendbares Dienstmodell
- Interaktive, publikationsreife Ergebnisse, die durch biologische Begründungen gestützt werden.
- Vertraut von globalen Pharma-, Biotech- und akademischen Institutionen
Egal, ob Sie eingestellte Verbindungen retten, neue Märkte erkunden oder IP-Anmeldungen unterstützen, CD Genomics bietet die Einblicke – und die Flexibilität –, die Sie benötigen, um mit Zuversicht voranzukommen.

Häufig gestellte Fragen zum Medikamenten-Neugebrauchsdienst
Q1: Welche Art von Daten muss ich bereitstellen?
Wir akzeptieren eine Vielzahl von Eingabeformaten, einschließlich roher Genexpressionsdaten (z. B. FASTQ, CEL), vorverarbeiteter Ausdrucksmatrizen oder Verbindungsinformationen wie SMILES-Strukturen. Wenn keine internen Daten verfügbar sind, können wir Ihnen helfen, relevante öffentliche Datensätze zu finden.
Q2: Können Sie mit eingestellten oder leistungsschwachen Verbindungen arbeiten?
Ja. Unsere Plattform ist speziell darauf ausgelegt, neue Indikationen für bestehende Verbindungen zu identifizieren – einschließlich eingestellter, abgelaufener oder geringpriorisierter Vermögenswerte – indem sie transkriptomische Signaturen, strukturelle Ähnlichkeiten und KI-Bewertungsmodelle nutzt.
Q3: Ist dies ein klinischer Dienst?
Nein. Alle unsere Dienstleistungen zur Wiederverwendung von Arzneimitteln sind nur für Forschungszwecke bestimmt. Wir bieten keine klinische Validierung, regulatorische Einreichungen oder diagnostische Anwendungen an.
Q4: Benötige ich Bioinformatik-Expertise, um Ihren Service zu nutzen?
Überhaupt nicht. Wir übernehmen alle rechnerischen Arbeiten – von der Datenbereinigung bis zur fortgeschrittenen Analyse – und stellen benutzerfreundliche, vollständig dokumentierte Berichte zur Verfügung, die bereit für interne oder externe Präsentationen sind. Unser Team steht Ihnen zur Verfügung, um Sie durch die Ergebnisse zu führen.
Q5: Was unterscheidet CD Genomics von anderen Anbietern?
Wir kombinieren fortschrittliche Bioinformatik mit einem hochgradig anpassbaren Workflow. Im Gegensatz zu generischen Plattformen passen wir jedes Projekt an Ihre Daten und therapeutischen Ziele an – unterstützt durch tiefgehende biologische Interpretation, Reproduzierbarkeit und reaktionsschnellen technischen Support.
Q6: Unterstützen Sie Folgeanalysen oder laufende Projekte?
Ja. Wir bieten optionale Beratungssitzungen, zusätzliche Analysen und Unterstützung bei der Integration unserer Ergebnisse in Ihre laufenden Forschungs- oder Lizenzierungsstrategien an.
Q7: Ich habe keinen vollständigen Datensatz – kann ich Ihren Service trotzdem nutzen?
Ja. Wir können mit Teil-Datensätzen, historischen Daten oder sogar nur mit zusammengesetzten Strukturen arbeiten. Falls erforderlich, helfen wir dabei, relevante öffentliche transcriptomische oder strukturelle Daten zu identifizieren und abzurufen, um Ihr Projekt zu unterstützen.
Q8: Wie umsetzbar sind die Ergebnisse? Kann ich sie nutzen, um interne Entscheidungen oder Förderanträge zu rechtfertigen?
Absolut. Unsere Ergebnisse umfassen vollständig nachverfolgbare Nachweise, auf Pfaden basierende Hypothesen und priorisierte Kandidaten mit Bewertungsbegründungen. Sie werden häufig in internen F&E-Bewertungen, Förderanträgen und der Positionierung von frühen Vermögenswerten verwendet.
Q9: Wie viel Input wird während des Projekts von meinem Team benötigt?
Minimal. Nach unserer ersten Beratung kümmern wir uns um die bioinformatische Pipeline. Sie werden über wichtige Meilensteine informiert, und wir stellen einen abschließenden interaktiven Bericht mit optionalen Überprüfungssitzungen zur Verfügung, falls erforderlich.
Q10: Kann ich bestimmte Krankheiten oder Ziele auswählen, auf die ich mich konzentrieren möchte?
Ja. Sie können Krankheitsbereiche von Interesse, Zielklassen oder biologische Mechanismen definieren, die Sie während der Analyse priorisieren möchten. Unsere Strategie ist stark an Ihren F&E-Fahrplan anpassbar.
Q11: Werde ich in der Lage sein, die Ergebnisse zu verstehen und sie nicht-bioinformatischen Interessengruppen zu präsentieren?
Ja. Unsere Berichte sind für interdisziplinäre Teams konzipiert. Grafiken, Bewertungsübersichten und verständliche Zusammenfassungen erleichtern die Präsentation der Ergebnisse gegenüber dem Management, Kollegen oder Investoren.
Q12: Besteht ein Risiko für Datenfreigabe oder IP-Exposition?
Nein. Alle Kundendaten werden unter strenger Vertraulichkeit behandelt. Wir arbeiten unter Geheimhaltungsvereinbarungen, verwenden sichere Server und teilen oder verwenden Ihre Daten in keiner Form wieder.
Q13: Kann Ihr Service Patentstrategien oder Lizenzierungsbemühungen unterstützen?
Ja. Viele Kunden nutzen unsere Erkenntnisse, um neue IP-Ansprüche zu identifizieren (z. B. für neue Indikationen oder Kombinationen), die 505(b)(2)-Wege zu unterstützen oder Lizenzvergaben mit validierter Umnutzungslogik zu stärken.
Referenzen:
- Pushpakom S, Iorio F, Eyers PA et al. "Arzneimittelneuentwicklung: Fortschritte, Herausforderungen und Empfehlungen." Nature Reviews Arzneimittelentdeckung 18, 41–58 (2019).
- Ashburn TT & Thor KB. "Arzneimittel-Neupositionierung: Identifizierung und Entwicklung neuer Anwendungen für bestehende Medikamente." Nature Reviews Arzneimittelentdeckung 3(8), 673–683 (2004).
- Pan X, Lin X, Cao D et al. "Deep Learning für die Wiederverwendung von Medikamenten: Methoden, Datenbanken und Anwendungen." arXiv:2202.05145 (2022).


